ESWC 2021 – SLOGERT
After some months of development, we are delighted to announce that our work on the Semantic LOG ExtRaction Template (SLOGERT https://github.com/sepses/slogert/ ) has been accepted for publication on ESWC 2021 conference!
SLOGERT is an approach to (semi-)automatically transform log data, e.g., network logs, into RDF graphs following a sequence of processes. SLOGERT supports automatic identification of rich RDF graph modelling patterns to represent types of events and extracted parameters that appear in a log stream.
The SLOGERT workflow is shown in the following Figure and described briefly below:
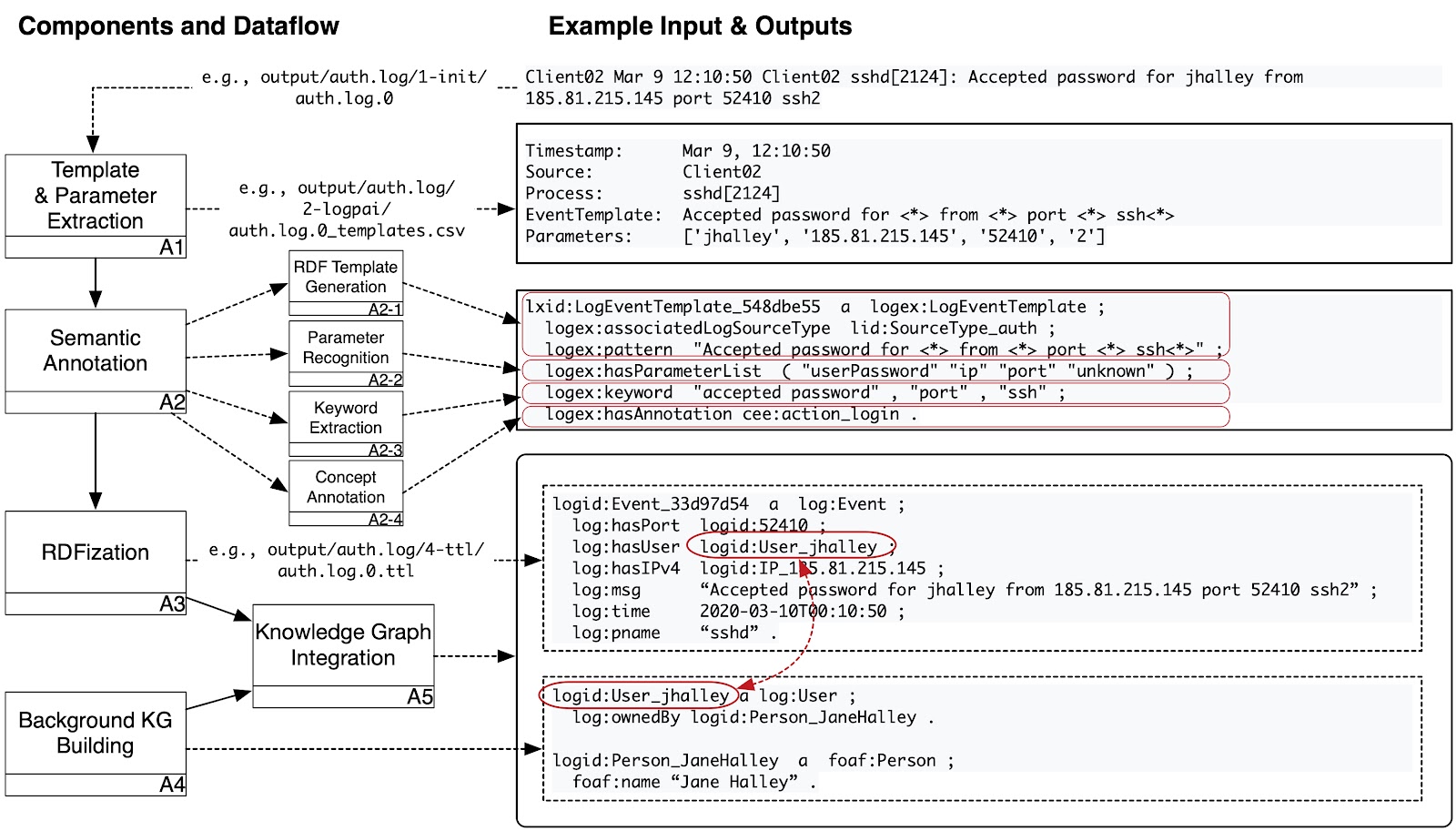
Figure 1 – SLOGERT workflow
- A1) Template & Parameter Extraction process takes in a log file and produced two files: (i) a list of log templates discovered in the log file, each including markings of the position of variable parts (parameters), and (ii) the actual instance content of the logs, with each log line linked to one of the log template ids, and the extracted instance parameters as an ordered list. For this process, we rely on LogPAI, a log parsing toolkit [2]
- A2) Semantic Annotation takes the log templates and the instance data with the extracted parameters as input for
- (A2-1) generates RDF rewriting templates that conform to an ontology and persists the templates in RDF for later reuse,
- (A2-2) detects (where possible) the semantic types of the extracted parameters,
- (A2-3) enriches the templates with extracted keywords (A2-3), and
- (A2-4) annotate the templates with CEE terms (A2-4).
- A3) RDFization. In this step, we expand the log instance data into an RDF graph that conforms to the log vocabulary and contains the single log file’. We currently rely on the Lutra engine [3] for the RDFization process.
- A4) Background KG building, where we build a Knowledge Graph containing information relevant to the log KG produced from step (A3).
- A5) KG Integration combines the KGs from the previously isolated log files and sources into a single, linked representation. Here, we rely on the standardised instance URIs to connect data from step (A3) and (A4)
We provide the pseudocode of SLOGERT main components (Figure 2), of which we described more precisely the processes on A1, A2, and A3.

Figure 2 – SLOGERT pseudocode
You can access the source codes, examples, and further information about SLOGERT in our GitHub repository [4], and we are looking forward to comments and feedback!
In the future, we are planning to continue working on SLOGERT to integrate it as part of our Auditability framework and explore the possibility to use it in a process mining pipeline. Stay tuned!
[1] https://openreview.net/forum?id=J9agdUNGhk [2] https://github.com/logpai/logparser [3] https://gitlab.com/ottr/lutra/lutra [4] https://github.com/sepses/slogert/